AI Tinkerers Toronto - AI Evals Workshop with Weights & Biases - Monday
Event Ended
This event has already taken place.




















AI Tinkerers Toronto - AI in Production: Evals & Observability Workshop in partnership with Weights & Biases is now live!
Come put your Python chops to work and build robust LLM apps with Observability and Evaluation! Note: Sunday and Monday workshops are the same. This is not part 2 :) See you there!

What is AI Tinkerers?
AI Tinkerers is a meetup designed exclusively for practitioners who possess technical, machine learning, and entrepreneurial backgrounds and are actively building and working with foundation models, and are eager to connect with like-minded technologists.
Who is this for?
- AI tinkerers and AI Engineers building or managing LLM-based systems in production
- Teams looking to replace ad-hoc “vibes-based” approaches with robust, future-proof evaluation pipelines
- Anyone interested in reproducible logging, real-time analytics, and frictionless iteration with LLMs
- Prior eval experience not required; basic Python experience is recommended for this workshop.
AI in Production: Evals & Observability Workshop
Join us for a hands-on workshop where you’ll learn to build and evaluate LLM-powered applications with robust observability practices. Leveraging tools from Weights & Biases Weave, we’ll walk you through common pain points and proven solutions to keep AI models performing in real-world production environments.
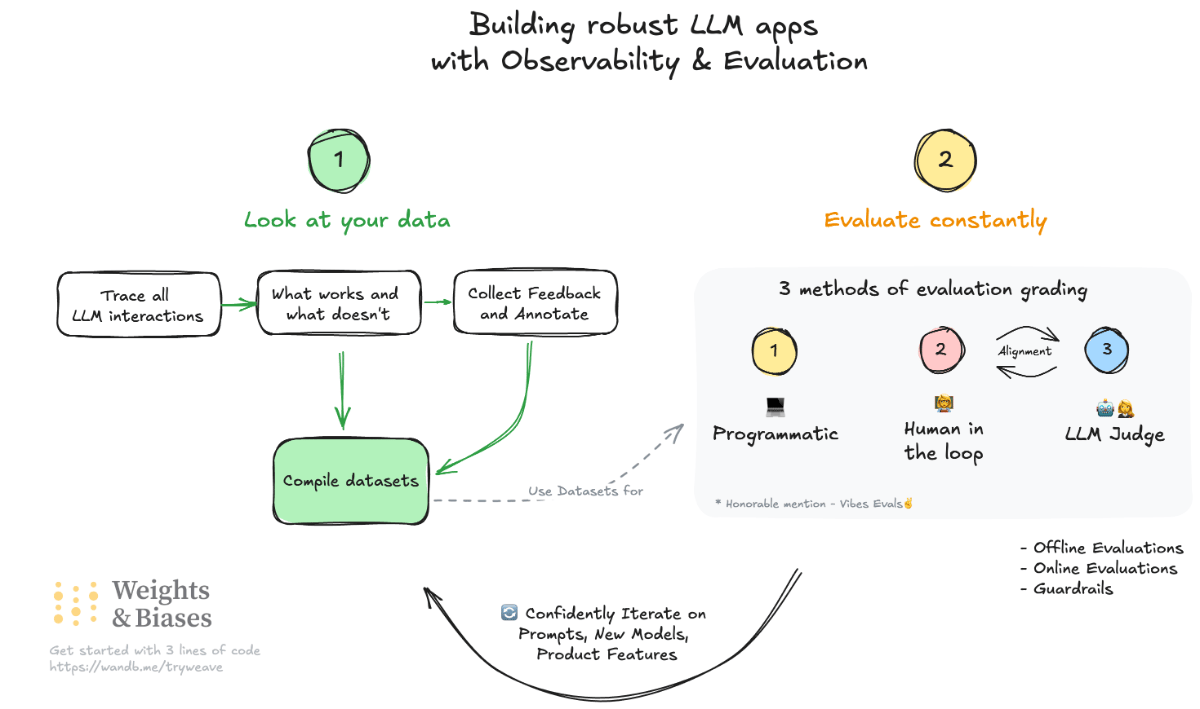
What You’ll Learn
-
Tracing LLM Interactions
Understand how to easily log each step of an LLM workflow, pinpoint issues faster, and maintain a historical record of inputs and outputs for better collaboration and troubleshooting.
-
Collecting & Leveraging User Feedback
See why user annotations and feedback loops are vital to refining model performance. Build interactive UIs that capture structured inputs from real-world usage.
-
Dataset Creation & Versioning
Learn best practices for compiling evaluation datasets from logs and user feedback. Manage versions effortlessly so you can track improvements over time.
-
Evaluation Pipelines
Dive into three primary evaluation methods:- Programmatic – String matching, regex checks, and structured output validation.
- Human-in-the-Loop – Manual labeling when tasks require nuance and domain expertise.
- LLM-as-Judge – Automate grading with a second, higher-quality (or specialized) model to evaluate output correctness.
-
Meta Evaluation and Improvement of LLM Judges
Building llm-judges is the beginning, evaluating the LLM judge, aligning with human judges, and more advanced techniques for a state of the art robust evaluation suite for your LLM application.
Agenda
-
6:00 PM - 6:30 PM: Arrival and Food
Grab refreshments and settle in for the session ahead.
-
6:30 PM - 7:15 PM: Trace & Compile
- Understanding Evaluation Metrics for LLMs
- Interactive Session: Implement observability tools and dashboards in real time
- 7:15 PM - 7:40 PM: Break
-
7:40 PM - 9:00 PM: Evaluations Hands-On
- Hands-On Lab: Build and refine an LLM evaluation pipeline
- Case Studies & Troubleshooting: Explore real-world scenarios to identify and solve common pitfalls
Featured Speaker
Anish Shah, Growth MLE – Weights & Biases
Anish is a distinguished Machine Learning Engineer on the AI Growth team at W&B, known for his approachable teaching style, Anish excels at distilling complex information into a digestible and easy to understand format. Anish will demonstrate step-by-step how to integrate Weights & Biases Weave into your AI workflows for maximum reliability and traceability.
What to Bring
- Your laptop. Code alongside practical examples. You’ll leave with a working pipeline for data collection, evaluations, and iterative improvements.
- An OpenAI API key
Sponsor
This event is supported by Weights & Biases Weave. With just a few lines of code, you can log and visualize LLM interactions in intuitive dashboards. Weave also helps you evaluate and compare multiple models—from GPT-4 to R1 to custom fine-tuned solutions—so you can confidently scale your AI applications.

Event Host
Hosted by the Human Feedback Foundation, a Linux Foundation AI & Data nonprofit advancing a more open and human-centric future for AI.

More Information:
- New to AI Tinkerers? Read the FAQ.
- Join our Discord: https://discord.gg/8WsqnC6Hk3.
Get ready to dive into LLM observability and evaluation! Whether you’re moving beyond prototypes or maintaining large deployments, this session will help prevent regressions, track performance, and optimize for the future. See you in Toronto!